I co-organized the ICML 2023 Workshop on Localized Learning. Accepted papers on OpenReview
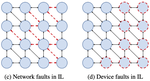
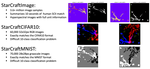
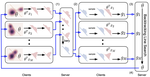
While global end-to-end learning has become the de facto training algorithm, it requires centralized computation and is thus only feasible on a single device or a carefully synchronized cluster. This limits learning on unreliable or limited resources devices, which may have limited connectivity, such as heterogeneous hardware clusters or wireless sensor networks. For example, global learning cannot natively handle hardware or communication faults and may not fit on memory-constrained devices, which could range from a GPU to a tiny sensor. To address these limitations, this project will study the fundamentals of localized learning broadly defined as any training method that updates model parts via non-global objectives.
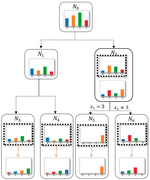
Topics include but are not limited to decoupled or early-exit training (e.g., [Belilovsky et al., 2020; Xiong et al., 2020; Gomez et al., 2022]), greedy training (e.g., [Löwe et al., 2019; Belilovsky et al., 2019]), iterative layer-wise learning (e.g., [Inouye & Ravikumar, 2018; Zhou et al., 2022; Elkady et al., 2022]), self-learning or data-dependent functions (e.g., batch normalization [Ioffe & Szegedy, 2015]), and non-global training on edge devices (e.g., [Baccarelli et al., 2020]). Out-of-scope topics include data-parallel training including standard federated learning (because the whole model is updated at the same time), alternating or cyclic optimization (because the algorithm uses a global objective), or algorithms that reduce memory requirements but still optimize a global objective (e.g., checkpointing, synthetic gradients, or global model-pipelined training).
References
D. I. Inouye and P. Ravikumar. Deep density destructors. In ICML, 2018.
Z. Zhou, Z. Gong, P. Ravikumar, and D. I. Inouye. Iterative alignment flows. In AISTATS, 2022.
M. Elkady, J. Lim, and D. I. Inouye. Discrete tree flows via tree-structured permutations. In ICML, 2022.
S. Löwe, P. O’Connor, and B. Veeling. Putting an end to end-to-end: Gradient-isolated learning of representations. In NeurIPS, 2019.
E. Belilovsky, M. Eickenberg, and E. Oyallon. Greedy layerwise learning can scale to ImageNet. In *ICML,* 2019.
E. Belilovsky, M. Eickenberg, and E. Oyallon. Decoupled greedy learning of CNNs. In ICML, 2020.
Y. Xiong, M. Ren, and R. Urtasun. LoCo: Local contrastive representation learning. In NeurIPS, 2020.
A. N. Gomez, O. Key, K. Perlin, S. Gou, N. Frosst, J. Dean, and Y. Gal. Interlocking backpropagation: Improving depthwise model-parallelism. Journal of Machine Learning Research, 23(171): 1–28, 2022.
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
E. Baccarelli, S. Scardapane, M. Scarpiniti, A. Momenzadeh, and A. Uncini. Optimized training and scalable implementation of conditional deep neural networks with early exits for fog-supported IoT applications. Information Sciences, 521:107–143, 2020.